Pxy x PX y Py y Py2
pX和pY是意思是,SX和SY单变量的方差过程X (i)和Y (i),分别;pXY =体育相关系数。PDF是“倾斜”pxy = 0(图7.9)。看到普利斯特里(1981:部分2.12.9其中),帕特尔和阅读(其中1996:第九章)和科孜et al .(2000: 46这章)的副法线分配的更多细节。
二维对数正态分布在更一般的情况下,牛和oy形状参数和尺度参数bX和,给出的
X (i) = exp牛■E ^啊,1)(我)+ ln (bx), Y (i) = exp oy与名词构成动词(0,1)(我)+ ln(通过),参见3.9节。它具有相关性(Mostafa和马哈茂德1964)
exp(牛oy■■Pe) - 1我^ [exp(牛)- 1][exp (oy) - 1]
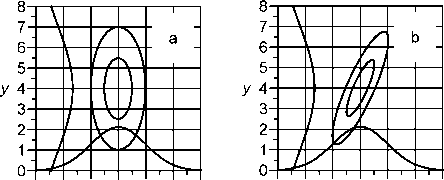
图7.9。副法线概率密度函数:等值线和边缘分布。参数:pX = 5, SX = 1, pY = 4, SY = 3 (a) pXY = 0或(b) pXY = 0.6。
2345678 2345678
x
图7.9。副法线概率密度函数:等值线和边缘分布。参数:pX = 5, SX = 1, pY = 4, SY = 3 (a) pXY = 0或(b) pXY = 0.6。
和PDF
f (x, y) = xy) 1 (1 - p |) 1/2
x实验
不均匀的二维AR(1)过程的时间间距是由
X (7.53) + EN (0, 1-exp {2 [T (i) - T(张)]/ tx})(我),我= 2,。n
+在(0,1-exp {2 [T (i) - T (i - 1)] /泰})(我),我= 2,。,n,白噪音创新方面相关
相关系数
相关系数
N(0, 1)(1),在(0,1)(1)
N (0, 1-exp {2 [T (i) - T(张)]/ tx})(我),Y
N (0, 1-exp {2 [T (i) - T(张)]/ rY})(我)
= (1 - exp {- [T (i) - T (i - 1))■(1 / tx + 1 /泰)})
我\ 1/2 x (1 - exp {2 [T (i) - T (i - 1)] / tx})
x - exp {2 [T (i) - T (i - 1)] /泰}j P£, i = 2,…, n,
相关系数
相关系数
在(0,1-exp {2 [T (i) - T(张)]/ tx})(我),在(0,1)
相关系数
在(0,1)(1),在(0,1-exp {2 [T (i) - T(张)]/泰})
我= 2 = 0,。,n。这个过程是严格固定的。它的属性是
E (X (i)) = E (Y (i)) = 0, VAR (X (i)) = VAR (Y (i)) = 1
偏差和标准错误的皮尔森相关系数分布的X (i)或Y (i)偏离高斯形状理论上可以使用参数近似描述偏差(高阶累积量)。冗长的近似公式是由Gayen(1951)和中川和妮基(1992)。的相关性公式用于实际的气候似乎是有限的,因为这些累积量的估计相当大的不确定性的有限数据集的大小。
另一个费雪的转换是霍特林(1953)
ZH型= z - 4 (n-iy•(7.58)
对于小n,霍特林的zH型分布接近高斯形状比费舍尔的z(罗德里格斯1982)。
斯皮尔曼等级相关系数是评价Pirie (1988)。费舍尔的z变换和使用正态分布并不是唯一的方法构造古典,近似为rs独联体。Kraemer(1974)提出一个替代学生的t分布的转换和用法。欧登(1973)为零情况下给ps = 0的确切PDF rs为n = 13到16。富兰克林(1988)研究了rs的精确零分布的收敛为n = 9到18岁的常态。至于rs的发起者,皮尔森(其中1924:393页)认为有“足够的证据表明,高尔顿处理的相关性排名前他甚至达到变量的相关性,并声称这是一个心理学家的贡献(即。,斯皮尔曼]一些三十或四十年后相关的概念似乎并没有我有效。”
两个连续变量之间的等级相关系数X和Y是(长臂猿和察克拉波提2003:其中11节)
,外汇(x)和(y)财政年度(边际)分布函数和f (x, y)是双变量PDF。的副法线PDF (Eq。7.49),相关系数pXY = pE可以分析解决了皮尔森(1907):
ps = - sin-1 (p£/ 2)。(7.60)
的情况下二维对数正态PDF (Eq。7.52), pxy与pE通过情商的地方。(7.51),解决了(表7.8)通过sim较真。考虑正态分布函数(Eq。3.49),表示为FN (x)。考虑进一步对数正态分布函数,FLN f (x) = ^ / LN (x) dx。在此,/ LN (x)是对数正态PDF (Eq。3.61)。然后,Fln (x) = FN (ln (x)) x > 0。
表7.8。等级相关系数,二维对数正态分布。ps决心从它的定义(Eq。7.59)通过随机二元数据密度(Eq。7.52)和计算平均和标准错误nsim = 1000000000模拟。对数正态参数:= = 0.0和< 7 x = 0, y = 1.0。
表7.8。等级相关系数,二维对数正态分布。ps决心从它的定义(Eq。7.59)通过随机二元数据密度(Eq。7.52)和计算平均和标准错误nsim = 1000000000模拟。对数正态参数:= = 0.0和< 7 x = 0, y = 1.0。
pS |
Accuracyb ps的 |
p£ |
0.3 |
4 <打败 |
0.3129 |
0.8 |
4 <打败 |
0.8135 |
一个平均nsim模拟。b标准错误/ nsim模拟。
一个平均nsim模拟。b标准错误/ nsim模拟。
点二列相关系数可以作为估计量的连续变量之间的线性关系的程度,X (i),和一个二分(二进制)变量,Y(我)。气候应用的一个领域是异常值的分析或极端气候(第六章),例如,Y (i) = 0意味着没有和Y (i) = 1一个极端的发生在时间T(我)。raybet雷竞技最新我们(对样本级别)p表示y (i)的比例值等于0;q = 1 - p;S0和Xi是意味着x与y (i)(我)值= 0和1,分别;和锡、X的模拟样本标准差估计值(Eq。7.8)。然后点二列相关系数(1982年Kraemer)定义为反应器= (pq) 1/2 (Si -) / sn, x。(7.61)
强化= rXY容易遵循。也许是泰特(1954)表明,如果(1)pXY = 0, (2) X的标准差(我)是独立于Y (i) = 1还是0,统计图则= (n - 2) 1/2rpb(1 -反应器)1/2 (7.62)
是作为学生的t和分发的n - 2自由度(3.9节)。这个数据被Mudelsee et al。(2004)研究大气变量之间是否存在关系(海平面压力,geopo-tential高度)和出现的易北河洪水间隔从1658年到1999年。由于持续的过程,生成的大气时间序列,Eq。(7.62)是适应代替n与有效数据大小(0.90确定为0.85 n n)。其他clima-tological反应器的使用以下的例子。Ruiz巴尔加斯(1998)研究一个大气变量之间的关系(涡度)和大降水的发生在南美,区间1983 - 1987,Giaiotti和Stel(2001)与雷暴发生位势高度在意大利,东北区间1998 - 1999。一个警告,也适用于这两个研究结果的解释就是持久性分析中被忽视。引导独联体为反应器研究了西弗斯(1996),发现良好的覆盖性能校准CIs已经对小数据大小的(n = 10)。
肯德尔的τ,采用4.4节(p。168)趋势测试,也可以使用(这是早期历史上)作为相关措施。对于趋势测试,我们计算交换的数量将{X(害怕)}™=我到相同(单调)秩序害怕{}™=我;相关的评估,我们将{X (i)}™= 1为相同的顺序{Y (i)}™= 1。哈米德(2009)提出了适应H0的统计检验:“零相关”考虑到连续依赖性(短期和长期)。
引导CIs的蒙特卡罗性能的相关系数进行了研究。大厅et al。(1989)发现一个循环的校准rxY带来大幅增加的百分比CI覆盖精度对二维对数正态白噪声和小数据大小(n = 8、10、12)。西弗斯(1996)证实了这一发现为n = 19和八个类型的白噪声的分布形状。以上研究使用普通引导重采样,因为缺乏连续依赖性。Mudelsee(2003)分析了引导BCa CIs rXY二维高斯分布和对数正态AR(1)过程与n 10至1000。他用pairwise-MBB重采样,认为可以接受的水平覆盖精度可以达到但串行的依赖减少了有效的数据规模在相当大的程度上。反对这项研究两个问题:块长度的选择是在一种特殊的方式(Eq。7.30)和研究过程是不相同的,严格固定的模型(7.53)式。非零的持久性有不利影响的观察(较大的偏差和RMSE)的相关性估计也量化了公园和李(2001),分析了rs在二元高斯AR(1)过程与n = 137。这些作者打了几重采样方法结合强力块长度选择(用标准差的RMSE rs)。他们的结论之一就是pairwise-ARB重采样nonparamet-ric某人的表现比成对版本重采样(3.8节)。 Papers from the psychology literature report about coverage performances of bootstrap CIs for quantities that are related to rxY and are of relevance to that branch of investigation, namely (1) correlation coefficients that account for range restriction or censoring of one variable (Chan and Chan 2004) and (2) the difference of correlation coefficients in overlapping data sequences (Zou 2007).
引导假说的蒙特卡罗性能测试后对相关系数进行了研究。马丁•豪(2007)认为:与非零pXY“pXY = pXY”。这是一个重要的测试用例,不仅对气候科学,因为它没有考虑到“稻草人”Ho:“pXY = 0,而是一个更现实的。raybet雷竞技最新这种测试可能供应信息的质量类似于CI(3.6节),和额外的信息关于测试能力。在零的非零pxy重新取样,一系列的“旋转”版本的原始双变量样本,(y (i)}™= 1对(x (i)}™= 1,使用(比斯利et al . 2007:无花果。1在其中)。这两个引用论文研究实证意义和权力二元白噪声的数据大小(从10到100),各种分布形状和几个pXY值(-0.5,0,0.4,0.8)。Belaire-Franch和Contreras-Bayarri(2002)执行一个类似的实验经验检验的意义和力量,采用AR(1)和马(1)模型的连续依赖性和使用某人重采样。总结上述蒙特卡洛实验的结果,我们得出这样的结论:测试实际的零假设pXY可以使用引导重采样准确执行。关于Ho的考验:Ebisuzaki pXY = 0,
(1997)研究了频域引导(5.3节)和经典的方法(通过n ^)使用时间间隔和二元AR(1)和AR(2)模型与n = 8、16、32和64年。他发现引导变异产生可接受小名义和实证拒绝利率之间的偏差,不仅为AR(1)而且AR(2)模型。大偏差发生小n和AR(2)参数接近1 a2 ^平稳性政权的边界(图2.4)。Ebisuzaki(1997)认为这个赤字穷人属性周期图的谱估计(第5章)。pyp和渔夫
(1998)没有研究引导,而是经典的方法(通过np)考虑连续依赖性。他们探索各种持久性模型(AR (1) AR (2), ARIMA),样本大小(15至50),自相关估计和平滑前相关估计的影响。前平滑构成的一种特殊情况另一种相关测量(安装7.1.1节)。之前他们的结论之一是平滑可以大大减少有效数据大小和导致减少功率的统计测试,看到还在Sun-climate段落之间的关系。raybet雷竞技最新
扔进垃圾箱和同步相关系数似乎小说估计工具适用于不平等的时间尺度的情况下。戴维森和欣克利(1997:例3.12其中)从一个密切相关的情况下,考虑一个例子,一些值(,说,Y (i))失踪。他们认为失踪的归责价值观”来获得一个合适的bi-variate F分布函数的估计,明年估计d(即。pXY],通常t (F)[即样本相关性。适当,rXY],然后重新取样”(戴维森,欣克利1997:90 p。其中)。归责方法是让一个回归的X(我)(i)(第八章)使用二元二次抽样样品没有缺失值。假设是随机值缺失(1976年鲁宾),这意味着,例如,没有范围限制和审查。算法将丢失的数据一般估计的目的提出了法官et al。(1977)和埃夫隆(1994)。关于时间间隔,我们有一个专注于一般情况下不规则和不丢失的情况下观察从一个等间距的网格。这就是为什么我们几乎完全不考虑污名。然而,在双变量设置,污名可能是一个有趣的估计的选择。 We note that when X and Y have no common time points, imputation is not straightforward to implement, whereas binned and synchrony correlation are so and may (if persistence exists and the time points of X and Y are well "mixed") help to recover information about the underlying correlation.
时间尺度不确定性也被Haam和Huybers(2010)作为一个问题影响的估计两个进程之间的关系。这些作者选择协方差衡量,认为即使间距和只允许其中一个两个进程受到时间错误。此外,时间表被认为只取离散值的错误。这个简化的设置,他们获得分析和数值结果的最大协方差的分布。这是反过来作为衡量经验协方差的意义。最后,Haam和Huybers(2010)使用这个测试研究之间的关系变化的害怕18 o石笋与时间尺度(错误)和大气放射性碳含量在全新世期间。他们无法拒绝零假设的协方差为零。这个结果应该谨慎评估一些因为之前分析系列已经实现甚至间距插值。
平滑引导由添加的噪声重新取样值(正态分布),x * (i)和y *(我)。(埃夫隆1982)的想法是规避引导离散分布的样本,这可能导致等数量的样本值一个糟糕的性能(戴维森,欣克利1997:3.4节在其中)。蒙特卡罗的研究(1987年西尔弗曼和年轻)的RMSE rYY和z证明样本标准差的平滑的优越性,特别是对z和小数据大小(n < 50)。年轻(1988)给一个规则调整平滑。可能引导CIs的报道相关估计可能受益于平滑。然而,更多的理论知识的应用平滑引导从连续时间序列相关的二元过程会有帮助。
引导的气候应用CIs皮尔逊rxY包括以下。黑带大师Kumar et al。(1999)使用重采样和百分位CIs来研究“削弱之间的关系印度季风和ENSO期间间隔从1856年到1997年。他们把正在运行的窗口长度的21年,决定使用点的全是印第安人的夏季季风降水的相关性(平均6月到9月)和赤道太平洋海面温度异常(6月到8月平均值)在窗口。获得相关信心带点态。这样的“运行相关性”通常用于探测的气候学,尽管缺乏理论框架非常数的相关系数(X(我),(我)]。Girardin et al。(2006)使用pairwise-MBB重采样和BCa CIs (PearsonT软件,7.7节)之间找到一个高度显著相关(转换)太平洋海面温度和西大气流动在过去大约150年在加拿大。Boessenkool et al。(2007)使用相同的方法来联系(proxy-derived)海底附近的水流速度在Iceland-Scotland岭NAO指数,1885 - 2004区间。他们发现,一个积极的指数(强海平面压力梯度)降低了水流;rYY = -0.42, 95%可信区间的值(-0.60;-0.20)提供量化的共变。这一发现对我们知识的大西洋经向翻转的应对气候变化—目前在科学讨论争论点。raybet雷竞技最新之前相关估计,国家审计署的时间序列已被过滤和插值预处理记录(不平等)流的时间点记录(d = 2.2);另一种方法是装箱过程(v7.5.1节)。Rothlisberger et al。(2008)也使用PearsonT研究南极温度的变化之间的耦合和海冰范围的气候在过去800 ka尘封。raybet雷竞技最新代理信息,关于温度从他们的D和海冰的通量seasalt Na(图1.5),来自雪佛兰景程圆顶C,也就是说,当前时间跨度最长的冰芯气候信息。raybet雷竞技最新的发现是在温和的气候阶段和关系强,而在寒冷的冰川条件较弱的(但仍然raybet雷竞技最新显著)。 Mudelsee (2003), introducing PearsonT, re-assessed the Sun-monsoon relation on Holocene timescales documented by ¿18O variations measured in a stalagmite from Oman (Neff et al. 2001). He chose the interpolation (unequal times) instead of the more appropriate binned or synchrony methods. He showed that the tuning of the (t(i)} of the monsoon proxy changed a nonsignificant correlation into a significant value, emphasizing, however, that the size of the time shifts of the tuning was smaller than the dating errors.
Sun-climraybet雷竞技最新ate关系在年代际时间尺度上,在间隔大约19世纪中期到现在,已经过去几年激烈讨论的主题。除了人为气候变暖信号(3.8节),可能存在信号变暖引起的太阳活动变化(图2.12)。两个原始论文的焦点。立斯·克雷斯顿森和拉森(1991)声称的存在密切关联的变化周期的太阳黑子周期和北半球陆地表面空气温度的变化区间从1866年到1985年。的变化时期的估计可能是使用方法不稳定光谱分析(5.3节),虽然立斯·克雷斯顿森和拉森(1991)首选一个更简单的方法通过平滑(Gleissberg 1944)和花时间最大值和最小值之间的差异。后来Sun-climate关系中的缺失环节(Svensmraybet雷竞技最新ark和立斯·克雷斯顿森1997)建议由银河宇宙射线通量的变化影响全球云覆盖。一系列的评论、批评以及这些发现发表回复。这本书的作者的印象是,的最新指控Laut(2003)和达蒙和Laut(2004)对两个原始的文件,其中包括“不可接受”的处理观测数据(达蒙和Laut 2004: 374 p。其中),没有反驳在同行评议的文献。这种印象一直支持Laut P(2009年,个人沟通),虽然立斯·克雷斯顿森E(2009年,个人通信)补充说,早期的交换参数(Laut和Gundermann 2000;拉森和立斯·克雷斯顿森2000)已经包括他的回答。 One point is that the northern hemisphere temperature record has been smoothed with a filter, apparently using pseudodata at the lower and upper interval bounds (Jones et al. 1986: Fig. 5 therein), and also the sunspot cycle record has been smoothed with a filter, using a technique equivalent to a boundary kernel. Both methods of boundary-bias reduction are described in the context of the inhomogeneous Poisson process (Section 6.3.2.3). They are standard techniques in time series analysis, and insofar as the quotation regards the use of those for graphical purposes, we think, contrary to Damon and Laut (2004), that the usage is acceptable. Regarding the influence of galactic cosmic rays on climate, IPCC-WG I (Forster et al. 2007: p. 193 therein) reports: "However, there appears to be a small but statistically significant positive correlation between cloud over the UK and galactic cosmic ray flux during 1951 to 2000 (Harrison and Stephenson 2006). Contrarily, cloud cover anomalies from 1900 to 1987 over the USA do have a signal at 11 years that is anti-phased with the galactic cosmic ray flux (Udelhofen and Cess 2001). Because the mechanisms are uncertain, the apparent relationship between太阳能可变性和云层被解释为结果不仅从宇宙射线通量变化调制日球层的太阳活动(Usoskin et al . 2004年)和solar-induced臭氧变化(Udelhofen和转运2001),但也直接从海洋表面温度改变通过改变太阳总辐照度(Kristjansson et al . 2002年)内部的变化由于厄尔尼诺-南方涛动(Kernthaler et al . 1999年)。在现实中,不同的直接和间接物理过程[…可以同时操作。”A statistical analysis of the association between solar cycle length and temperature on basis of the original data (Fig. 7.10) may shed some light on the issue. Let X(i) denote cycle length and Y(i) temperature. Using the digitized data and omitting the earliest solar data point, for which no corresponding temperature point exists in the original paper, yields n = 23; the spacing of the resulting bivariate series is, as the cycle length, not constant. Pearson's correlation coefficient is rXY = -0.956. Persistence time estimation with bias correction yields fX = 45 a with 90% percentile CI [9 a; 78 a] and = 106 a [8 a; 128 a]. The lag-1 scatterplots (Fig. 7.10c, d) show the residuals (Eq. 2.12) to reflect clearly less autocorrelation than the original data, attesting to the suitability of the AR(1) persistence model. The large persistence times come obviously from the high amount of smoothing performed on both records. The effective data size is n^ = 2.13. This tiny value prohibits any interpretation of a determined association; the large absolute value of rXY may well be spurious. Insofar as the quotation from Damon and Laut (2004) regards the criticism of oversmoothing prior to correlation estimation, we think they are completely right; see also Pyper and Peter-man (1998). A recent review (Lockwood and Fröhlich 2007) found that since 1987, trends in solarraybet雷竞技最新气候营力和全球平均表面空气温度去相反的方向。显然,它应该有意义学习的不光滑的记录和其他(代理)文件太阳能和气候变化。raybet雷竞技最新可以进一步扩展视图在时间和使用也气候模型分析工具(冷缩et al . 2003年)。raybet雷竞技最新引导CIs应该有利于评估结果quantitatively-not只有那些声称协会也反对趋势。第二个建议是考虑到应用程序的多个测试(5.2.5.1节),因为时间间隔的选择和预处理的类型给研究者更多的自由。这些措施将使测试更Sun-climate关系在年代际时间尺度上,尽管现有的知识似乎不允许期望身体明显raybet雷竞技最新的影响。
CT C

O O
o o
有限公司有限公司
E E
o o
i-I-I-I-I-I-I-I-I-I-I-I-I-r
1850 1900 1950 2000
有限公司有限公司
CD光盘
cp cp
E E
CD光盘
1-I-I-I-I-I-I-I-I-I-I-I-I-I-I
12 11 10 9的周期长度(一个)
图7.10。太阳活动周期长度和北半球陆地表面空气温度异常,1866 - 1985。周期长度的时间序列(平滑)(开放的符号)和温度异常(填充符号);b周期长度和温度异常之间的散点图;c lag-1散点图、标准化的周期长度(符号)和标准化的周期长度残差(开放符号);d lag-1散点图、标准温度异常(符号)和标准化的温度异常残差(开放的符号)。(时间序列数字化值从立斯·克雷斯顿森和拉森(1991:图2在其中)。)
气候与自相关假设测试的应用程序包括以下调整。Rothman(2002)研究了X (i)之间的相关性:锶同位素比值和Y (j):同位素分馏总有机碳与沉积碳酸盐过去500 Ma。这两个变量(纽约纽约= 48 = 46)测定在独立的样本海洋沉积岩石,因此独立的时间尺度。相关分析的目的是获得一个代理大气中二氧化碳浓度的变化在如此漫长的地质时期。作者X (i)值插值到泰(j)计算时间和斯皮尔曼等级相关系数r = -0.4。他利用频域引导(5.3节),考虑到自相关效应(2001年Rothman)并确定一个片面的假定值为0.17。假定值的准确性可能受到以下因素的影响:(1)前平滑的X (i)已经应用,(2)可能是第二个插值(等距离)计算周期图(第五章)是必要的,(3)数据大小有限,(4)不平等的时间尺度和插值可能负偏差引入rS(7.5节)。净效应还不清楚:虽然因素(1)会让P增加,因素(4)会让P降低,因此,提高信心。pyp和Pe-terman(1998)使用他们的方法通过n ^测试H0:“pYY组= 0”二元的样本的存活率不同股票的鲑鱼在阿拉斯加湾(时间间隔从1957年到1989年,每年的分辨率)。爱德华兹和理查森(2004)研究方法之间的关系年际变化的时机不同官能团的季节性周期(例如,硅藻和甲藻)和海洋表面温度,时间间隔1958 - 2002。他们发现显著的相关性,这突显出气候变化对海洋深海生物气候学的影响。raybet雷竞技最新
因果关系是不一样的相关性。然而,哲学概念(第一章)的一个动作之间的关系(变量X)和反应(变量Y)需要时间箭头和应与本章的主题。这个关系已经发表在统计概述(巴纳德1982;针对1998)和物理文献(杭和Vejmelka 2007)。一个因果关系的概念来自于信息的量化公式理论和使用可预测性的想法:“我们说Y (i)导致X (i)如果我们能够更好地预测X (i)使用所有可用的信息比如果信息除了Y (i)被使用”(其中格兰杰1969:p。428)。推理对这个“格兰杰因果”需要时间序列的分析,{t (i), x (i), y (i)} n = 1,并可能使用统计模型,线性或非线性,可能时间间隔参数(格兰杰和林1994;斯特恩和考夫曼2000;Triacca 2007),参见第8章。气候是下面的例子。二元线性回归模型拟合的温度时间序列(X (i))北部和南部(Y (i))半球,覆盖区间从1865年到1964年(考夫曼和斯特恩1997; Stern and Kaufmann 1999). From the estimated time lag between the two variables, the authors concluded the existence of a south-to-north causal order "generated by anthropogenic activities that increase the concentration of greenhouse gases globally, but which increase the concentration and effects of sulphate aerosols mainly in the Northern Hemisphere" (Kaufmann and Stern 1997: p. 42 therein). This conclusion was criticized as inconclusive by Triacca (2001), who preferred the direct demonstration of Granger causality of CO2 changes on temperature changes; that, however, had been done by Tol and de Vos (1998) using a linear regression model with a prescribed lag. This simple model type has also been utilized for demonstrating an ocean feedback (daily wintertime sea-surface temperature) on the NAO, performed (Mosedale et al. 2006) using a 50-year long simulation from the climate model HadCM3 (Fig. 1.9). More advanced, nonlinear descriptions result from employing the mutual information (Fraser and Swinney 1986; Granger and Lin 1994),
假设对数的基础两个,/ XY量化多少关于X的信息可以预测的基础上,y的样本互信息的概念已经扩展到高维混沌系统和相关的属性(普里查德和赛尔1995)。这样的一个扩展,它被称为广义冗余,受雇(Diks和Mudelsee 2000)研究变量之间的因果关系的多更新世气候raybet雷竞技最新。测试的假定值的零假设“零信息”(没有格兰杰因果)确定使用某人重采样(Diks和DeGoede 2001)。发现(Diks和Mudelsee 2000),从内插系列,是害怕改变18 o(代表冰体积)做格兰杰原因害怕变化13 c(代表的力量形成的北大西洋深层水),这种耦合并增加对更新世晚期。其他信息理论措施可以应用三个变量时,X, Y, Z,可用;覆盖过去400年的数据分析发现,太阳活动的变化似乎“占全球温度的一个小规模的行为比温室气体”(弗迪斯2005:p。026222 - 7在其中)。最近对因果关系检测使用信息理论方法(Hlavackova-Schindler et al . 2007年)从气候学给了更多的例子。Barnard (1982: 387 p。其中)指出,“因果关系并不一定意味着相关性为后者通常是测量”。He gives the simple nonlinear model,
与X (i)均匀分布在(- 1,+ 1),就是Y (i) - 1和+ 1之间变化;这个模型已经pXY = 0。设计合适的非线性过程,依赖措施替代皮尔森和斯皮尔曼是线性的措施,有一种艺术。格兰杰et al。(2004年):第652 - 651页。其中)建议措施应该有以下属性:
1。它是定义良好的连续和离散变量。
2。是归一化零如果X和Y是独立的,和谎言在0和+ 1之间。
3所示。测量的模量等于统一(或最多)如果有可测量的准确(非线性)的关系,Y = m (X)说,在随机变量之间。
4所示。它等于或有一个简单的关系(线性)相关系数的二元正态分布。
5。它是度量,即。“距离”的,这是一个真实的措施,而不仅仅是发散的。
6。测量连续不变,严格增加转换这是有用的,因为X和Y是独立当且仅当^ (X)、^ (Y)是独立的。不变性非常重要,因为否则聪明或无意转换会产生不同程度的依赖。”
格兰杰et al。(2004)研究了几个依赖措施许多非线性模型通过蒙特卡洛模拟。
7.7技术问题
斯皮尔曼等级相关系数的方差是副法线流程(大卫和锦葵1961:情商。(Z)在其中)
1 36
-0.42863279 x n3 (pyy组+ 0.08354697 pyy组+ 0.04257246 pyy组+ 0.01687474 pyy组0.1551301 + 0.00664071 pxy + 0.00270655 pxy + n2 (pyy组0.18443407 - 0.057362293肽yy -肽yy
0.01329883 - 0.02271732 pyy组+ 0.00757524 pxy + pxy + n (0.36837259 pyy组+ 0.44738882肽yy - 0.08427574 pyy组
0.19943375 - 0.27929901肽yy - pxy - 0.1386106 py2y 0.21015257 + 0.07179677 pyy组+ 0.06467162 pyy组+肽yy pxy 0.07923733 + 0.28589798 pyy组+ 0.31704425 pxy +
PearsonT (Mudelsee 2003)是一个Fortran 90程序计算rYY BCa CI与pairwise-MBB重采样。该软件可在这本书的网站。
这篇文章有用吗?