随机模拟的降水和流速及流水量流程
何塞·d·萨拉斯豪尔赫·a·拉米雷斯PAOLO BURLANDO和罗杰·a·皮尔克,Sr。
hydroclimatic过程的随机模拟降水和河川径流等已经成为标准工具分析许多与水相关的问题。仿真表明“模仿”的行为基础过程这现实的表征。为此许多经验,基于数学/物理,数学/随机的基础,基于模拟/物理和物理/实验室基础模型和方法在文献中被提出和发展。本章强调基于随机模拟和概率技术。同时,重点将降水和流速及流水量过程,虽然此处包含的许多方法和模型也同样适用于其他hydroclimatic过程如蒸散、土壤水分、地表和地下水的水平,和海洋表面温度。
随机模拟允许一个获得同样hydroclimatic序列过程也可能发生在未来。他们是有用的对于许多水资源等问题(a)估算储层系统的设计能力不确定的流水量,(b)评估水资源系统的性能满足用水需求预测不确定系统的输入下,(c)估计干旱特性,诸如干旱长度和大小根据模拟水流在考虑供水系统的关键点,(d)中底层的输出变量的分布地下水流动方程(例如,水头),考虑到分布参数(例如,渗透系数)和边界条件,(e)建立-
手册的天气、气候和水:大气化学、水文、和社raybet雷竞技最新会影响,由托马斯·d·波特和编辑布拉德利·r·科尔曼。约翰•威利& Sons ISBN 2003©0-471-21489-2公司。
荷兰国际集团(ing)的旅行时间的不确定性和传播污染物在多孔介质作为函数的参数不确定性的地下水污染传输模型,和(f)分析大规模气候变化和全球气候变化的影响在供水和接下来的计划和可用性raybet雷竞技最新操作的水资源项目。
1随机模拟的降水连续时间沉淀
已经申请点过程的建模理论的连续时间沉淀自Le Cam60建议一个泊松过程模型的降雨淋浴。让我们假设风暴N (t)的数量在一个时间间隔(0,t)到一个给定的点是泊松分布与参数(I =风暴到达率。)指图1 (a), n风暴到达间隔(0,t)有时tx,…t„。风暴的数量在任何时间间隔kT T也泊松分布的参数。进一步假设降雨量R与暴风雨的到来是白噪声(例如,R可能伽马分布)和N (t)和R是独立的。因此,降雨量rx,……rn,对应于风暴发生有时tx,…, tn。这样一个降雨产生的过程被称为泊松白噪音(PWN)。
累计降雨间隔(0,t), Z J (t) = ^“我”Rj是一个复合泊松过程。还连续累计降雨量不重叠的时间间隔,即。,离散时间降雨过程(参见图1),由Yl - Z (iT)给出Z (- T)。我= 1,2,欧美的基本统计特性假设Z (T)是由一个PWN模型已被广泛研究。11“20其自相关函数pk (Y)等于零落后大于零,这与实际观测(如。,px (Y) = 0.446小时降水在丹佛机场车站六月份的基于1948 - 1983年的记录。)尽管这个缺点,PWN模型可以用于预测年度precipitation20和极端降水事件。10,而不是假设降雨发生瞬间为零时间可以考虑降雨强度随机时间D和我,如图1 b。这被称为泊松矩形脉冲(PRP)模型。86一个共同的假设是,D和/独立和指数分布。图1 b显示了PRP过程与n风暴间隔(0,t)发生有时t {…tn,强度和持续时间有关
(/ ',dx) (/„, dn)。然后,风暴可能会重叠,欧美的聚合过程
成为autocorrelated。虽然比PWN PRP模型更好的概念,当应用于降雨数据仍然有限。86因此,替代模型基于集群的概念已经被提出。
Neyman和Scott69建模星系的空间分布的概念最初提出集群。Le Cam60 Kavvas Delleur, 51和others30‘82’86”88年应用连续降雨空间聚类的概念模型。Neyman-Scott集群过程可以被描述为一个二级机械
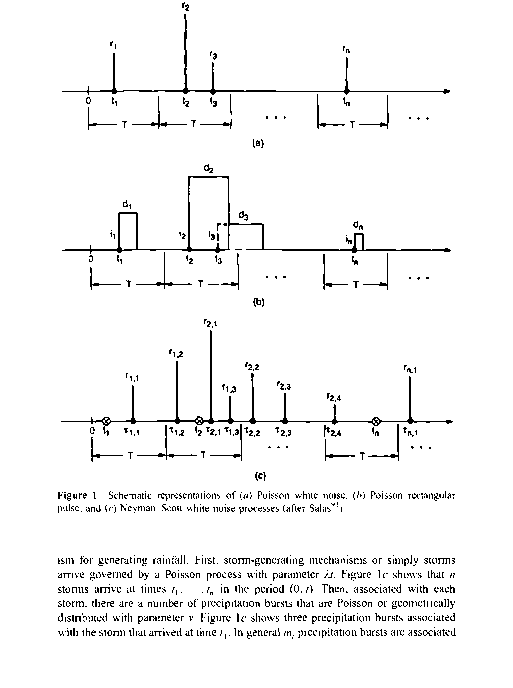
tj的风暴到达时间。此外,发生爆炸的时候,相对于风暴的起源i - t,英国《金融时报》可以认为是指数分布的参数(例如,在风暴Fig.lc三爆发起源于第一个位于倍t,,, t, 2,和tl3相对于?,)。然后,如果降水破裂所描述的是一个瞬时随机降水深度R,由此产生降水过程被称为Neyman斯科特白噪音(NSWN),而如果降水破裂是矩形脉冲降水过程被称为Neyman-Scott矩形脉冲(NSRP)。
参数估计Neyman-Scott (NS)模型一直是主要的主题研究在过去的二十年。9“22”71“51”通常的估计基于矩量法,虽然其他方法已经被提出。82年“51”29日明显主要估计问题是参数估计为一个基于数据水平的聚合每小时说,可能是明显不同于那些从另一个层面的聚合数据估计,每天说。11“30”71“86问题似乎是,数据汇总,信息丢失和相应的二阶统计没有足够的信息给予可靠的估计的参数生成过程(模型),并且,因此,他们变得明显偏大的方差。例如,大量的模拟研究是由Cadavid et al.11基于NSWN模型(已知)人口参数:1 = 0.102 x 10 /分钟盐以及jS = 0.00221 /分钟,fx = 24.36 /,和l / v = 0.072(参数几何分布的集群大小)。每小时和日常系列被用来估计的时刻(意思是,标准偏差,和lag-1 lag-2相关系数)的参数估计。结果如表1所示。显然,尽管生成机制是已知的(NSWN),不可靠的估计参数时获得每日值。估计基于加权最小二乘的方式各种时间尺度的时刻是一个选择。10的22,物理方面的考虑可能是有用的在建立约束的一些参数,初始化估计基于统计考虑,确定和比较拟合模型参数与一些已知的物理特性。17 Koepsell Valdes54应用这些概念使用时空集群模型提出了Waymire et al.116建模降雨在德克萨斯州和指出了难以估计的参数,即使使用物理方面的考虑。
除了泊松过程的类和Neyman-Scott集群过程,其他类型的时间沉淀模型已经提出,如那些基于Cox流程,103更新流程,7“31和Barlett-Lewis流程。40 87年同样,替代时空多维降水模型已经开发(例如,史密斯和Krajewski104)。此外,所有降水模型基于集群点和流程提出最新的在某些方面是有限的;例如,他们不包括日周期中观察到实际对流降水过程。49 71此外,Rodriguez-Iturbe et al.89等人提出了这个问题,非线性动力学和混乱可能是有用的方法对于某些水文气象过程,如降雨。最后,优秀的评论艺术领域的状态made32和许多研究与降雨分析、建模和可预测性已编译的一些特殊问题
参数(单位) |
人的价值 |
估计每小时的数据” |
估计从日常数据” |
103 x(1 /分钟) |
0.102 |
0.103 |
0.091 |
ßx 103(1 /分钟) |
2.210 |
2.300 |
1.630 |
人工智能(信用证) |
24.360 |
23.990 |
7.010 |
1 / v |
0.072 |
0.072 |
0.247 |
“估计基于12系列的大小为36456小时,每天12系列的大小为1519。从Cadavid et al。”
“估计基于12系列的大小为36456小时,每天12系列的大小为1519。从Cadavid et al。”
期刊(例如,j .达成。流星。,32卷,1993;j .地球物理学。104卷,Res。D24, 1999)。
每小时、每天、每周的降水
我们已经看到在前面的部分中,模型和属性连续累积沉淀在不重叠的时间段,即。离散时间沉淀,可以从连续时间降水模型。然而,一个可以制定降水模型直接在每小时,每天,每周的时间尺度。在这些情况下,马尔可夫链的理论已广泛应用于模拟的文学不仅降水(在离散时间),但许多其他水文进程年代如河流、土壤水分、温度、太阳辐射、和
7 n 49骶髂关节在水库蓄水。••••
认为X (t)是一个离散值的过程,始于0和开发时间,即。我= 0,1,2,P (X (t) = xt \ X (0) = x0, X (\) = x1,…X (t - 1) = X,过程的概率是_ j] X (t) - xt给出它的整个历史。如果这简化概率P (X (t) = X, X (t - 1) = xt_ |,),这个过程是一个一阶马尔可夫链或一个简单的马尔可夫链。因为X (t)是一个离散值的过程,我们将使用符号X (t) = / ', / = 1,…,r oiX (t) = x„在j r是代表一个国家和州的数量;例如,在建模每日降雨量可能会考虑r = 2 j = 1干天(没有雨)和j = 2潮湿的一天。定义一个简单的马尔可夫链的转移概率矩阵P (t),一个方阵元素P ^ t) = P (X (t) - j \ X (t - 1) = /] ij双。此外,qj {t) = P (X (t) = /) / = 1,……r的边际概率分布链是在任何国家在时间t j和#——(0)是初始状态的分布。此外,如果P (t)并不依赖于时间,马尔可夫链是一个齐次或固定链,在这种情况下,符号P和py使用。 The estimation of some probabilities that are useful for simulation and forecasting of precipitation events are the «-step transition probability p\j\ the marginal distribution qj(t) given the distribution qj(0), and the steady-state probability vector q*. These probabilities can be determined from well-known relations available in the literature.39'118
估计为一个简单的马尔可夫链数量来估算元素p¡j的转移概率矩阵。常见的评估方法包括矩量法和最大似然。39测试是否一个简单的马尔可夫链是一个适当的模型在考虑过程,可以检查一些假设的模型和降水过程的一些相关属性是否复制(例如,比较概率讨论从观测数据获得,此外,Akaike信息标准一直在选择有用的马尔可夫链的顺序models.15 48
虽然在某些情况下,简单的马尔可夫链可能适合表示降水的变化,往往更复杂的模型可能是必要的。例如,在日常全年降雨过程建模,马尔可夫链可能随时间的参数(例如,两个国家的马尔可夫链,过渡概率p¡j可能会有所不同的,估计可以安装三角级数来消除样本variations90)。高阶马尔可夫链在其他情况下可能是必要的。Chin15分析每日降水记录超过100站在美国大陆和得出结论,一般二、三阶模型为冬季而首选一阶模型夏季是更好的。此外,最大似然估计的傅里叶级数系数为每日rainfall90交替更新流程和马尔可夫链和混合模型与周期性的马尔可夫链每小时降雨量(占日周期的影响)suggested.49
月、季节和年降水量
建模等长的时间尺度的降水月通常是比等短时间尺度的日常简单,尤其是因为长时间尺度的自相关变得较小或可以忽略不计(例低frequency21除外)。在这种情况下建模降水在给定网站每月发现的概率分布。通常每个月需要不同的分布。另一方面,在半干旱和干旱地区季节性降水数据可能包括一些季节的零值,因此降水混合随机变量。让Xvx =降水年v和赛季z,并定义PT (0) = P(十五r = 0), z = l,…有限公司(公司=数量每年季节)。然后,FXx (x) = Pt (0) + (1 - r / 3 ((J)] FVTiVT > 0 (a)是赛季的累积分布函数z的FXx {x) -罗马帝国<九、委托方私自复印)和| \ v > o < ") = P (x < x \ > 0)。因此,季节性降水预测需要估计Px(0)和FVi | vt (a) > 0。等分布的对数正态分布和log-Pearson用于拟合经验分布的季节性降水。建模降水在几个网站,一个必须考虑intersite交叉和边缘分布的相关性(在每个站点上)。连续随机降水,常见的建模方法是转换成正常,然后使用lag-0多元模型建模转换后的降水(类似于建模方法streamfiow如第二节)。建模的年降水量与建模季节性降水,即。,确定边缘分布外汇(x)或条件分布Fx ^ x > 0 (x),这取决于具体情况。同样,建模的年降水量在几个网站通常是基于将数据转换为正常,使用多元正态模型。
2随机模拟的流速及流水量
如果可以开发一个在连续时间随机水流模型,然后,原则上,模型的属性和每日、月度、年度流速及流水量。已经进行了一些尝试开发模型基于物理的河川径流过程在连续时间的原则。然而,20聚合流的模型,可以从这样的连续时间模型,成为数学上的繁琐和有限的操作水文适用性。53理解升级的规则模型和参数为研究一直是一个具有挑战性的课题。通常大多数的模型可用于水流模拟在连续时间和短时间尺度,如每小时,是基于转换的降水径流通过物理或概念性原则。这样的随机特性的降水输入和其他有关流域的水文循环过程转移到一个随机水流输出。这类的例子模型由SHETRAN26和PRMS.59 SHETRAN模拟水流“连续”沿着河边网络通过求解偏微分方程的物理过程,而人口、难民和移民事务局semidistributed概念模型,模拟每小时和日常流速及流水量。然而,在这一节中,我们主要关心的是随机水流模型,可以显式地来自底层的物理或概念上的基础关系直接从河流流域的水文过程或数据。
连续时间每小时,每天流水量模拟
在连续时间范围内水流的模拟需要的配方模型结构能够繁殖的宽动态范围的流水量波动。如前所述,应用程序的连续时间随机方法和短时间尺度河流建模是有限的,因为复杂的非线性关系,描述precipita-tion-streamflow过程的时间尺度。早期尝试模型每小时,每天流水量后使用自回归(AR)模型是基于标准化和转换。然而,随机模型本质上是基于过程的持久性不正确的肢体和衰退特征典型的每小时,每天流成因。散粒噪声或马尔可夫过程和传递函数模型提出了日常流动模拟和一些有限的成功繁殖的肢体和recessions.110上升
然而,有趣的工作已经完成了一些成功利用conceptual-stochastic模型。例如,Kelman52应用分水岭的概念表示考虑存储直接径流和地表水和地下水的影响。直接径流建模相当(l)模型指标函数产生间歇性和其他组件的建模使用线性水库。凯尔曼的模型产生合理的结果生成每日流动鲍威尔河、田纳西。还在萨拉斯Obeysekera96和建议的方法鼓掌et al ., 16 Murrone et al.68提出了短时间内径流conceptual-stochastic模型。一个三级概念径流组件和一个随机地表径流模型的每日响应分水岭。基本流建模三个线性水库代表深层含水层的贡献与同期反应,与年度更新含水层,地下径流。地表径流被视为一个不相关的点的过程。建模降雨量作为一个独立的泊松过程,上述方案导致多个散粒噪声流速及流水量的过程。该模型有效地繁殖流速及流水量的变化。此外,断断续续的每日流速及流水量过程已经被结合modeled25凯尔曼的概念与产品models94和伽马AR models28方法和通过使用一个三态马尔可夫链描述水流的流速及流水量和一个指数衰减的发病recession.1
每周,每月,季节性河流
单周期模型。平稳随机模型可以应用于建模每周、每月、季节性标准化后和季节性河流。这种方法可能是有用的,当季节相关性不变化。一般来说,模型结构周期相关,例如周期自回归(PAR)和周期自回归和移动平均(帕尔马)更适用。29 92年的一个例子是帕尔马(1,1)model97
青年志愿,r = Hx +«HrOv。t-l - Hz-l) +£v r ~ 01, t£v, t - 1 0)
uT, (¡z >), T,如:)模型参数。当O是零,模型(1)成为帕尔马(1,0)或票面价值(l)模型。低阶帕尔马模型如帕尔马(1,0)和帕尔玛(1,1)已经广泛用于模拟月度和每周flows.3'I8“43”84 ' 92 ' 120
帕尔玛模型可以来源于物理/概念的原则。考虑所有hydrologie流程和参数在流域不同,它已经表明,季节性河流属于帕尔马的家庭模式。96或者,一个常数参数模型与定期提出独立的残差。16的一个可取的属性随机模型季节性河流的季节性的保存和年度统计数据。然而,这样的双重保护统计很难用简单的模型如票面(l)或(2)不相上下。因为这个原因在1970年代水文学家转向所谓的解集模型(参见第三节)。这种简单的PAR模型的主要缺点繁殖季节和年度统计数据一直缺乏足够的相关结构。帕尔马模型有更灵活的相关结构比PAR模型提供保护季节和年度统计数据的可能性。一些水文学家认为,帕尔玛模型参数太多了。然而,一个人不能希望模型如票面价值(1)比它可以做更多的事,例如,复制简单lag-1明显相关,而未能重现时间滞后和统计相关性更高的聚合。另一个繁殖季节和年度统计是乘法的家庭模式。
盒子和Jenkins5最早提出乘法模型。这些模型的特点连接变量T和yvz_i青年志愿和yv_l McKerchar Delleur66使用乘法模型的对数差分后原级数模拟和预测每月流水量系列。因为这样的乘法模型没有考虑周期的相关性,使用差分,以减少或消除这样的周期性。然而,他们不能够繁殖季节性的协方差结构,不能建立信心与考虑季节性预测的局限性。这个问题是因为称为乘法模型不包括周期参数。模型(周期参数),可以克服上述局限是乘法帕尔马模型。例如95年,乘法帕尔马(1,1)x(1.1)„,模型是写成
zv。t = ^ l。^ v-l。T + 4 > \, xZv, z - \ + fiv。T ^
~®1 t£它们t ~ ~ 1美元,t£V, t - 1 + 1®, t ^ 1, t£它们,t - 1
害怕zV T - yVtX uT和橙汁T, @1t, < f > l z, 9 l z, (e)模型参数。这个模型已经成功应用了模拟尼罗河流动。
上述限制帕尔马和乘法帕尔马模型建模水文时间序列的要求底层系列被转换为正常。另一种没有这个需求是PGAR (l)模型建模季节性流动周期相关结构和周期性的伽马边缘分布。27认为y是一个周期性的相关变量与一个带三个参数γ边缘分布位置Az,规模,和形状参数不同t, t = 1 <»(t =数量的季节)。然后,新变量zv T =青年志愿T - A是一个可以用两个参数γzv T = ^ > TzV T_1 + (zv T_1) Twv r (j) =周期自回归系数,盎司=周期自回归指数,西弗吉尼亚州T =噪声过程。这个模型有一个周期性的相关结构相当于票面价值(l)的过程。已经应用于每周流速及流水量系列几个美国河流States.27结果表明这样PGAR模型要优于基于对正常的模型(如对数变换后的PAR模型)在繁殖的基本统计数据通常被认为是水流模拟。水流模拟,此外,非参数方法能够繁殖密切proposed.100历史分布
帕尔马和PGAR模型更有用的建模流在短暂的流。在这些流流动是间歇性的,这一特点并不由上述模型表示。周期性的产品模型是更为现实的,而是94年伯努利容易Bv T是一个周期相关
(l, 0)过程,zv T可以是一个未修正的或相关的周期性过程与给定边际分布,和B和z是相互的。性能及应用这些模型的模拟一些短暂的间歇每月流流在literature.14的已报告94
多点周期模型。在建模季节性水流在几个网站,多元PAR和帕尔马模型通常使用。6 92年“42”,例如,97多元帕尔马(1,1)模型
Zv T =青年志愿的z - | x;| x是一个列参数向量与元素个\…■年代,fi”> T和0 T n * n周期参数矩阵,噪声项ev T是一个列向量与£正态分布(ev I) = 0,£(ev Te ^ T) = rT和E (£v xk) - 0 k 0,和n =数量的网站。此外,它假定ev T是未修正的t_1。该模型的参数估计可以由矩量法,尽管解决方案并不简单。删除移动平均任期(3),即所有t 0 t = 0时,产生了一个简单的多元帕尔马(1,0)或票面价值(l)模型。这个简单的模型被广泛用于产生季节性水文过程。进一步简化上述模型可以促进参数估计。假设< J > T, T©Eq。(3)对角矩阵,多元帕尔马(1,1)模型为每个站点可以解耦成单变量模型。 To maintain the cross correlation among sites ev T is modeled as ev T = Bx£ where E(£ f )= I and E(£ ,) = 0 for k ^ 0. This modeling scheme is a contemporaneous PARMA(1,1), or CPARMA(1,1), model. Useful references on this type of models are available in the literature.42,84,92,97
一年一度的河流
自回归(AR)和自回归和移动平均(ARMA)模型一直是最受欢迎的为单身网站和多点年度水流模拟模型。具体来说,低阶模型已经广泛应用于生成年度series.29流动,42岁,61,62,72,92
单稳态模型。AR(1)模型被定义为y = n + 4 > (y - \ n) + ' <■■其自相关函数pk = (f > pk, = 4 > k指数随着时滞k的增加衰减。这个模型是一个健忘的原型模型因为pk趋于零相对较快,因此h - *■\很快在E (R * *) ~ nh (R *„* =新范围样本均值的累积离职)。更多功能比AR(1)模型ARMA(1,1)鉴于6□,42岁,97年
y = j”+ (¡> (yt-1 - j”) + (4)
其自相关函数pk = (l - - 0) (l - 200 + d2)的1 ^ 1是比这更灵活的AR(1)模型,因为它取决于两个参数(j)和9。的ARMA过程能代表长记忆的依赖,72 ' 9 '许多河流的属性是很重要的。AR和ARMA模型假设底层系列是正态分布,这一假设并不总是适用于年度流速及流水量系列。同时可以规避这一假设通过将倾斜系列转换为一个大约正常系列,一个直接的方法,它不需要一个转换是一个可行的选择。γ自回归(雀鳝)过程y = - (j)) + < $ > yt_ \ + t),提供了这样的一个替代,y,伽马分布参数X,,,英国《金融时报》(位置、规模和形状参数,分别),(j) =自回归系数,和t) =噪声项。雀鳝(l)模型具有相同的自相关函数的AR(1)模型。雀鳝的评估程序和应用模型模拟年度流速及流水量literature.28系列可以找到
AR、ARMA和雀鳝模型是有用的在常年河流流速及流水量流程建模,然而他们是不够的在一些短暂的间歇过程,如水流流速流。间歇过程可以建模为y = B, z,欧美=非负断断续续的变量,Bt =依赖(1,0)伯努利过程,z =正面价值连续autocorrelated变量,例如,一个AR(1)过程,和Bt和z,认为是相互不相关的。因此,由此产生的产品欧美是间歇性和自回归过程。这些模型已经申请短期降雨和间歇流流程建模。94“13”最后,其他类型的模型,如分数高斯噪声。64折线,6转移水平,93和FARMA42已经提出了代表年度流速及流水量时间序列的某些特殊性质。例如,转移模型模拟的能力水平和突然变化时间序列,一个属性在许多hydroclimatic过程中所观察到的。
多点固定模式。建模的多个水文时间序列广泛需要。考虑列向量欧美元素y V \]……vj”, n =系列的数量(数量的变量)正在考虑。多元AR(1)模型as65定义
Zt型=次- (x, | x是一个列向量的u(1),还有……e是一个列向量的正常噪音< {1,…与零均值,这样,每个E (eteJ) - F和E (E, eJ_ k) - 0 k 0,和美元和F n * n的参数矩阵。此外,它假定et与2 t_x不相关的。模型(5)是一个健忘的原型模型为多个系列,已广泛应用于操作水文。92年29“42”62”同样,多元ARMA(1,1)模型可以写成Eq。(3)除了参数$ &不依赖于时间。
除了低阶多元AR模型,充分利用多元ARMA模型常常会导致复杂的参数估计。73年92年因此,已经提出的简化模型。例如,一个同时代的ARMA(卡玛)
模型结果如果< 1 >和0是对角矩阵。这个概念,倡导的萨拉斯et al ., 92 Stedinger et al ., 106和Hipel McLeod42可以扩展到一般情况下。的关系意味着只有并发的y值的依赖被认为是重要的。此外,参数矩阵的对角化允许“脱钩”模型组件单变量模型,模型参数不需要联合估计,和单变量建模程序可以使用。因此,单变量自回归滑动平均模型(p, q)安装在每个地方每个r},“\ / = 1未修正的,但同时与variance-covariance矩阵t .因此,参数,< / > ' s和0在每个模型中,可以使用单变量估计估计可以建模过程和e的e = Bq,£是正常与e (| = /) = 0 k ^ 0。注意,一个没有反对帮派成员相同的单变量自回归滑动平均(/,,q)模型为每个站点。
3时间和空间解集模型
解集模型,即。,降尺度模型在时间和/或空间,随机水文学的重要组成部分,不仅因为我们的科学兴趣的理解和描述的特点,水文过程的时空变异性,也因为实际工程应用。例如,许多水文设计和操作问题需要每小时降水数据。因为每小时降水数据并不常见的每日数据,一个典型的问题是缩减规模或每日数据分解为每小时的数据。同样,为简化大规模系统的分析和建模涉及大量的降水和流速及流水量,时间和空间崩溃过程是必要的。本节简要讨论一些经验和数学模型和程序的时间和空间崩溃的降水和河流。
解集的降水
一般站降水数据的解集在给定的时间间隔定义为更小的时间间隔沉淀经验。74为例,用表或图表,可以做24小时的解集(每日)沉淀成6小时降水。更完整的解集方案developed.41 119。Hershenhorn和Woolhiser41认为每日降雨量和一个模型获得,一天之内风暴的数量大小,数量,时间,到达时间为每个风暴。他们表示,模拟降雨序列与观测值进行比较。尽管上述模型创新,他们不满意,即。,他们是复杂的,需要很多的原始数据转换获得合理的结果。另一个缺点是缺乏灵活性的间隔。
另一个正式的短期降雨将计划是由Cadavid et al.11解集模型均假设PWN NSWN
(参见第1部分)作为底层rainfall-generating机制。制定PWN解集算法的模型是基于分布的移民的数量N Y条件总降水的时间间隔,白噪声项给定N的分布和Y,和到达时间的分布取决于N算法使用模拟PWN样本时表现良好。解集方案基于NSWN模型更为复杂。它表现良好在模拟并记录样品提供,使用的模型参数解集规模类似的控制过程。主要的缺点是不相容的参数估计在不同聚合水平在第一节指出。最近,基于人工神经网络的降雨崩溃suggested.8
爱泼斯坦和Ramirez24开发了一种多尺度、线性回归统计气候反演方案基于解集模型的瓦伦西亚和Schaake111由raybet雷竞技最新雷竞技csgo
缩减规模hydroclimatic Y是一个矩阵的值(例如,降水),X是一个矩阵的高档hydroclimatic值,a和B是参数矩阵和独立标准正态偏离的年代是一个矩阵。所有条款在上面的方程是时间的函数,和降尺度模型条件按时通过大规模的演化,x参数估计,基于矩量法,导致保护的第一,二阶时刻各级聚合。
流速及流水量数据的解集
低阶PAR模型的缺点,当申请模拟年径流统计繁殖季节性流动导致解集模型的开发,比如Valencia-Schaake(6)模型。在这个模型中,季节性流动的建模与仿真是在两个或两个以上的步骤来完成的。第一年度流进行建模,以繁殖所需的年度统计数据(如。基于ARMA(1,1)模型);然后合成生成年度流动,进而分解到季节性流动通过Eq。(6)。而variance-covariance季节性流的属性数据保存和生成的季节性流加起来每年流模型(6)不保留一年的第一个赛季的covar-iances之前,任何季节。绕过这个缺点,Eq。(6)已被修改为我= AX +是+ CZ,其中C是一个额外的参数矩阵和Z是一个向量的季节性较上年同期值(通常只有上赛季的前一年)为每个站点。每年6进一步改进和修正假设模型,再现了S % x和Sxz suggested57以及每年计划,不依赖于模型的结构Syy然而繁殖时刻,SYX, Sxx。05
上述解集模型参数太多了,一个问题可能是重要的特别是当网站很大的数量和可用的历史样本容量很小。Lane56设置为零的一些参数,这样在上面的解集模型
Yz = ATX + B, e + CtFt_ !t = 1,……(u (7)
用更少的参数模型。参数估计和适当的调整,这样季节性值添加具体年度值在每个站点上可以找到literature.56的97
估计问题可以简化如果崩溃是在步骤(阶段或级联),这样涉及到矩阵的大小,因此参数的数量减少。6为例,每年直接流可以分解为月度流在一个步骤(这是通常的方法),或者他们可以在两个或两个以上的分解步骤,例如,季度流程第一步;然后每个季度流进一步分解到月度流动在第二步。然而,即使在后者方法中,相当大的矩阵的大小会导致当赛季的数量和网站的数量很大。桑托斯和Salas98提出逐步崩溃方案以这样一种方式,在每一步崩溃总是做成两部分或两个赛季。这个方案会导致2 x 2的最大参数矩阵大小单解集和2 n x 2 n多点。解集模型,繁殖季节统计和季节性流每年流假设对数正态分布的协方差季节和年度流动还建议。36个107年也基于nonpara-metric程序提出了时间崩溃。
尽管解集随机水文学的主要开发和实用工具,还为什么某些周期模型的问题仍然未能重现年度统计数据。因此,更复杂的模型,如帕尔马模型提出了和发达国家在1970年代和1980年代早期。他们的能力为繁殖季节以外的统计特性探讨了Obeysekera Salas70和Bartolini Salas.3
4时间和空间聚合模型
在崩溃中,聚合(升级)建模方法处理水流过程在两个或两个以上的聚合级别或时间尺度。然而,这两个概念有很大的不同。在崩溃,建模和生成过程是落后的一个模型并生成年度流动第一,然后每月,每周,每日连续流获得的解集的步骤。另一方面,在颞聚合,前进的过程。,一个模型,生成每日流动,然后先后每周,每月,每年流建模和生成。聚合方法的基本前提是,连续的随机特征时间尺度规定那些在任何级别的聚合或时间尺度。数据之间的关系在不同的时间尺度literature.50已经探索
聚合流水量过程的建模方法是由维基亚等al.112假设每月流动遵循一个标准(l)和帕尔玛(1,1)过程,结果表明:年度流动产生的模型是平稳ARMA (1,1)。上述概念和结果带进光流水量模型之间的结构连接和兼容性(及其参数)的各种时间尺度。尼日尔河的水流数据Kaulikoro,非洲,被用来说明一些聚合的概念,特别是在与繁殖季节性流动时的年度相关结构建模的PAR(左)和帕尔玛(1,1)模型。70年比较结果表明,参数和相关图的ARMA(1,1)模型的年度流动来自季节性流动的模型,获得的结果从帕尔马(1,1)模型明显优于从票面价值获得(l)。此外,获得的结果取决于季节的数量被认为是今年(如月度、季度),和更好的结果,随着今年赛季的数量变得越来越小。
Bartolini Salas3聚合的概念扩展到包括聚合不仅季节到一年,从数周甚至数月,月的赛季,赛季年。例如,帕尔马的聚合(2,1)月度流动导致帕尔马(2,2)双月刊流动;反过来的聚合帕尔马(2,2)双月刊流动也给了帕尔马(2,2)季度流动。此外,如果这种季度流聚合为年度流动,那么模型是平稳ARMA (2, 2)。部分聚合的概念已经应用到尼日尔河季节和年度流动,结果显示的优越性和帕尔马(2,1)和帕尔玛(2,2)模型相对于其他模型进行繁殖的variance-covariance属性年度流动。聚合的应用概念建模尼日尔河的季节和年度流动在不同时间尺度建议需要使用帕尔马模型水流建模与仿真如果想繁殖季节和年度第一和二阶统计数据。等传统模型PAR (l)只是不足等建模流程的尼日尔。季节和年度流动模型的常用的方法是使用不同模型对不同时间尺度,无视模型在不同时间尺度之间的兼容性。聚合的概念和结果讨论了在这一节中指出,这样的传统方法和模型水流模拟必须避免。
类似的推理在时间聚合申请空间聚合流水量过程。例如,一个可以假设一个流网络组成的第一,二,三阶流。首先考虑建模流两个一阶流交界处。自然,该模型在一个网站立即下游结必须源自二元模型定义在两个上游网站,每一个支流。反过来,二次流的流动模型加入流动的另一个,说,二阶流必须定义模型的下游流立即结,等水流顺流而下流网络。因此,水流模型必须在时间和空间尺度上的兼容。
5扩展问题和缩小规模
理解、描述和建模本地、地区和全球气候与水文非线性的相互作用,生物物理和生物地球化学过程目前地质的一些最具挑战性的问题。raybet雷竞技最新不仅是高空间和时间变化的管理过程和边界条件,但这种变化发生广泛的尺度。分布式水文模型需要高分辨率的输入数据。在所有hydro-logic变量,降水是至关重要的在水和能源预算土地surface-atmosphere接口,及其在水文和大气模型准确的表示是至关重要的。降水是复杂的结果相关的大气和陆地表面过程。它有极端变化多年从秒时间尺度和空间尺度从不到米到数百公里。水文行为的敏感性降雨的时空变异性是由于降水和地表特征之间的非线性相互作用控制降水进入土壤水和径流的变换。降水的建模需要对统计学的理解结构的空间-时间的沉淀和理解物理过程管理的进化降水时空尺度的范围。因为规模差异、降雨降尺度耦合需要全球大气模型和水文模型(或区域)。一般来说,降尺度计划可分为两大类,动力与统计降尺度方案。
在动态方案、气候和土地利用变化场景开发地raybet雷竞技最新区和地方尺度上利用区域和当地大气模型,例如,区域大气建模系统(公)的科罗拉多州立大学。这些模型是由边界条件推导出从观察和全球大气模型的输出。这样,基于大气模型作为身体动态插入器(即。基于物理的降尺度)。公羊被耦合到地表方案(LEAF-2),水文模型(TOPMODEL),一个地区的生态系统模型(世纪)。因此,动力方案编码多个非线性和复杂的地方和区域的交互和反馈,明确。79 115年然而,试图解决过程有没有减少天平使用基于物理的模型迅速导致计算效率低下和可怜的理解是有限的物理过程在小尺度上的行为。其他大气模型如NCAR models33和宾夕法尼亚州立大学/ NCAR中尺度模式,版本5、19已经使用了动态缩小规模。
在统计降尺度中,次网格时间和空间尺度气候变化的细节,特别是降水,得到了这样的统计特征的时空变异性hydroclimatic字段保存规模的函数。统计技术通常基于线性或非线性回归,从非线性动力学方法,人工神经网络,马尔可夫过程,乘法随机级联模型,等。回归方法的限制之一是,它们适用的只有一个强大的大规模参数和地区和当地气候之间的关系已被确认(通常不会这样),而他们是有效的只有在空间和时间范围内的观察。raybet雷竞技最新虽然统计降尺度计算高效,但它不能包括上面所提及的次网格尺度的物理反馈明确,很难对大气过程与区域生态和水文过程。另一方面,基于乘法随机统计降尺度级联模型可以扩展功能(也就是繁殖。,尺度不变性)、集群和间歇性的特点与相对温和降水在空间和时间的计算负担。
直到最近,大多数的降尺度方法提出了在文献中只有处理空间变异性的降水场的时间演化描述的领域通常是独立于空间缩小规模。唯一的时间相关结构占是造成大气模型的动态产生的降水场较大的空间规模或编码的时间观测的进化。因此,在一般情况下,这些计划不充分和适当的占(即时间相关结构。、持久性)在次网格尺度降水的字段。
动力降尺度
动力降尺度可以被认为是对模型的四个基本类型:一类是强烈依赖于大规模数值天气预报侧边界条件,底部边界条件,初始条件。第二个类型已经忘记了初始条件但是依赖于观察侧和底部边界条件。第三种类型是大规模的模型运行,只有强迫表面边界条件,并输出用于缩减规模区域模型。第四种类型是当一个真正的全球气候模型(与耦合海洋、大气、海冰大陆、景观过raybet雷竞技最新程,等等)用于提供横向区域模型的边界条件。这是政府间气候变化专门委员会(IPCC)类型的降尺度除了只有一组有限的地球系统raybet雷竞技最新营力(如二氧化碳的辐射效应,太阳能日晒)包括在政府间气候变化专门委员会的方法。总结的例子(IC =初始条件;LBC =侧边界条件,BBC =底部边界条件;BBC的识别包括底界面通量):1型ETA4使用观察IC, LBC,和英国广播公司(BBC);2型PIRCS34”35使用观察LBC和英国广播公司(BBC);3型ClimRAMS迫于CCM3结合观察SSTS102使用观察到英国广播公司(BBC);和类型4地球系统全局模型使用区域模型缩减规模。45观测约束的解决方案变得不那么像我们从1到4型。 Thus预测能力将减少1型4。
对当代模型,如atmospheric-ocean全球环流模型(AOGCMs),无论是AOGCMs还是地区(type 4模型)包括所有重要的人类对气候系统的影响。raybet雷竞技最新土地利用变化的影响,生物地球化学效应的氛围,例如,由于二氧化碳的增加,,例如,污染气溶胶的微观物理学的影响尚未包含在这些模型。因此,现有的模型只能解释为敏感性实验运行,不预测,预测,甚至scenarios.80
此外,对动态缩小规模,按照目前的应用,没有高档的AOGCM区域模型的反馈,即使所有重要的大型规模(GCM)人为干扰是包括在内。AOGCM也有空间分辨率不足以正确定义外侧区域模型的边界条件。尖刺外壳和Warner2显示外侧边界条件地区大气模型的主要强迫与传播特性有关极地西风带。数值天气预报(类型1和2的模型),使用的观测分析,初始化一个模型保持现实主义即使退化的一个组成部分的粗糙模型分辨率的全球模型。这种现实主义持续一个星期左右的时间,当作为一个区域的横向边界条件数值天气预报模式。这不是真正的AOGCMs数据不存在影响的预测。区域模型不能重新插入模型技术,当它是如此依赖于侧边界条件,无论多么好的区域模型。
统计降尺度
中尺度大气模型的输出如公羊或观测数据等的NEXRAD(下一代雷达)网络通常是在网格尺寸更大(如。0(103年至104年)m]比与分布式hydrologie模型(例如,在10°米)的顺序。地表系统响应励磁的从大气中,如降水、和反馈水分到大气中,例如,通过蒸散和潜热通量。激励和响应在广泛的尺度空间异构,包括次网格尺度(如。,< 0 (104)m],这一次网格空间变异性对高档的大小和分布产生重大影响和低档次的地表通量的交互是非线性的。占这个时空异质性对hydrologie建模和描述是重要的土地surface-atmosphere交互。23‘78’83此外,统计降尺度,除了要求AOGCMs准确的预测未来,也要求统计方程用于降尺度改变了区域大气和地表条件下保持不变。没有办法测试这个假说。事实上,它不太可能是有效的自区域气候不是被动的大规模的气候条件,但预计将随时间变化较大的尺度和反馈。raybet雷竞技最新这个问题的更多细节关于降尺度一直reported.8
回归计划。大规模和局部范围气候领域之间的关系可以通过回归建立方案。降尺度的最直接的方式就是直接插值。这种方法很容易和有效的申请顺利海平面压力或温度等不同领域但不适合非光滑间歇降雨等领域。一些例子在回归方案(1)的方法(基于主成分分析、典型相关和回归分析)称为气候预测
-
.")
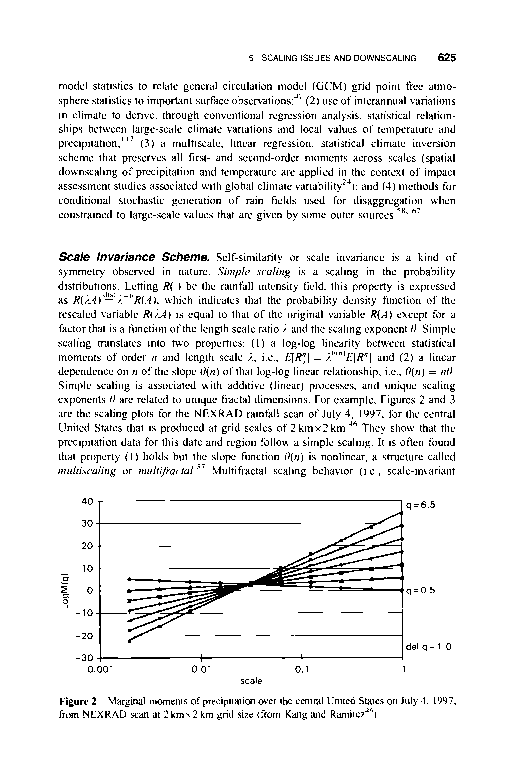
- 图3斜坡边缘的时刻对数尺度函数的NEXRAD扫描降水在美国中部7月4日,1997年,在2公里x 2公里网格大小(从康和Ramirez46)。

.")
行为)的标度指数在空间被发现分布的降雨
37岁,75109
在降水的时间分布。尺度不变性和间歇性的降水可能被利用来开发rain.63的吝啬的随机模型
乘法随机瀑布被用来生成模拟扩展的光谱指数的分形领域观察到的降雨量。根据缩放级联选择发电机产生的光谱。值得注意的是,如普遍的多重分形模型,109 / j-modcllX或log-Poisson model101提出了。为了说明,我们将在下面讨论随机级联models.38, 46 75年
离散随机瀑布分发质量连续定期细分^维立方体。这个过程的示意图如图4所示。最初的立方体,长度尺度L0,每一层分成了相等的部分,其中b > 2 d是分支数。第z subcube n级别的细分来标示后(有我= b”subcubes n)在水平。subcube’是表示的长度尺度Lm和无因次空间范围被定义为Xn = LJL0 = b ~民盟。大规模数据集上通过不同层次的分布发生如下。第一个初始数据集(n = 0级)分配一个nonran-dom密度R0,即。,一个初始质量RqLq。subcubes \,我~…第一次细分后,b (n = 1级)分配密度R (j Wx(,),即。,质量R0L ! \ Wx (i), W独立同分布随机变量(iid)级联生成器。这个乘法过程继续通过所有n级联的水平,所以质量subcube’
Hn {K) = R0LdnY \ Wj{我)。
在E [W] = 1;因此各级平均质量守恒的随机的级联。
5扩展问题和OOWNSCALING 627分支数量- * !参数:p . y . O
第三级联

第三级联
Ria-S ^ W.WjWj
(一)离散随机层叠modd
图4为一个二维离散随机层叠模型原理图:(a)离散随机层叠模型(从康和Ramirez46)。
随机模拟的降水和STflEAMFLOW流程branrlting Dimb9 ^ 4 paiamAfr fr m。
-
")
- 第三级联(o-3)
")

(b) reratanmiftnc hjaarciBcaJ randtm modd
图4为一个二维离散随机层叠模型原理图:(b)非参数随机层叠模型(从康和Ramirez4 *)。
级联的极限质量得到n - > oc。它被认为是堕落如果总质量为零的概率1。非退化取决于W的分布,它要求E [W] - 1条件感到满意。极限质量subcube / (^ (Aj,)满足递归关系:害怕^ (Aj,) =鳍(镑)Z ^(我),因为我= 1 b”iid随机变量在哪里、分布式Zx = / j ^ (A0) /
/(一)=害怕uoo (A0) / 7 ?0Z0 for all i, n. The cascade limit mass ¿/^(AJ,) is given by the product of a large-scale low-frequency component ¿u„(A'n), and a subgrid subgrid (i.e., subcube) scale high-frequency component Z^(z'). The latter term represents subgrid-scale variability at each level of cascade development.
随机级联展览时刻扩展行为的哪些属性级联振荡器W可以估计。样本空间的时刻被定义为Mn (q) = XlLi tioo(镑),q =时刻秩序(q - 0,仅包含了非零极限质量之和)。对于大的n,样本的时刻应该收敛于合奏的时刻,但因为他们发散到正无穷n -►oo或收敛到零,收敛速度/散度的时刻规模被认为是相反的。在一个随机的级联,合奏时刻显示的双对数线性函数规模Xn。这种比例关系的斜率称为Mandelbrot-Kahane Peyriere (MKP)功能:/ j (q) = \ - q +日志/;E \ Wq]。MKP函数包含重要的信息分布的级联发电机W,从而描述降雨的扩展属性。同样,样本矩的斜率比例关系可以被定义为z (q) = lim _ ^ n[日志Mn (q) / -日志kn)。对于大型n (Xn 0)和特定范围的q,山坡上的比例关系为样本和合奏瞬间收敛,即。r (q) = dyh (q)。在数据分析中,样品的比例时刻用来估计z (q)和级联振荡器的分布函数,从级联模型的参数可以推断。
对于间歇降雨时空数据,它是可取的,P (W = 0)是正的。为此一个级联间歇性模型生成器W是写成W =, B是一种间歇性发电机所谓的/我建模和Y是一个严格的积极的随机变量。/ ?模型域分为雨季和nonrainy分数基于以下可能性:P (B = 0) = 1 - B - 1”和P (B = b1”) =(我是一个参数和E [B] = 1。霁模型不允许变化的积极的部分限制的大型组件质量害怕你„各级(“„)(n它假定非随机值R0LndbP”)。变化的是
继续阅读:随机预测降水和流速及流水量流程
这篇文章有用吗?
读者的问题
-
奥马尔1年前
- 回复